Apache SeaTunnel and Paimon: Unleashing the Potential of Real-Time Data Warehousing
Hello everyone, my name is Jiang Xiaofeng, a senior development engineer at Bilibili and also an Apache Paimon PPMC member. Today, I would like to share with you the topic of “Analyzing the Architecture of Apache SeaTunnel and Its Integration with Apache Paimon”.
Speaker Introduction

Jiang Xiaofeng
Senior Development Engineer at Bilibili
01 Design Goals of Apache SeaTunnel
In the rapidly evolving big data industry, various technologies such as databases and data warehouses continue to emerge and develop. For enterprises, how to synchronize data from heterogeneous data sources to the target end has become a crucial issue. Especially after the retirement of Apache Sqoop, real-time synchronization, full database synchronization, and Change Data Capture (CDC) have gained attention from enterprises. With regard to these data integration scenarios, Apache SeaTunnel aims to build the next-generation data integration platform.
The core mission of Apache SeaTunnel is to address the essential requirements of data integration in the big data domain. It provides users with efficient, user-friendly, and fast synchronization connectors for data synchronization. Apache SeaTunnel is a high-throughput, low-latency, distributed, and scalable data integration platform designed to tackle various challenges in data integration.

Firstly, there is a wide variety of data sources with different types, including databases, messaging systems, and data lakes. As a data integration platform, Apache SeaTunnel needs to support a large number of data sources. Secondly, individual data sources also have different versions, and compatibility issues between versions are often difficult to resolve. In addition, high resource utilization can impact the data source when synchronizing multiple tables in MySQL, as frequent processing of Binlog data may have a significant impact. Moreover, big data transactions and schema changes can also affect downstream systems.
Furthermore, there are other challenges such as excessive connections during JDBC synchronization, which may result in delayed data synchronization. Each company has its own unique technology stack,
leading to a high learning curve for data integration.
The synchronization scenarios are complex, including full and incremental synchronization, CDC synchronization, and whole-database synchronization.
Data quality is difficult to ensure, with common issues such as data loss or duplication, making it challenging to guarantee data consistency.
Additionally, most tasks cannot be rolled back or resumed in case of exceptions during the synchronization process.
Lastly, due to the lack of monitoring metrics, it is challenging to identify potential issues during the data synchronization process.
Apache SeaTunnel proposes solutions to these problems.
02 Architecture of Apache SeaTunnel V1
When discussing the architecture of Apache SeaTunnel, let’s start with the architecture of V1. The V1 architecture heavily relies on the computing engine, specifically Spark and Flink engines, as all tasks need to go through the computing engine for completion. Although the computing engines provide ample computing power, it also results in slower data synchronization speed.
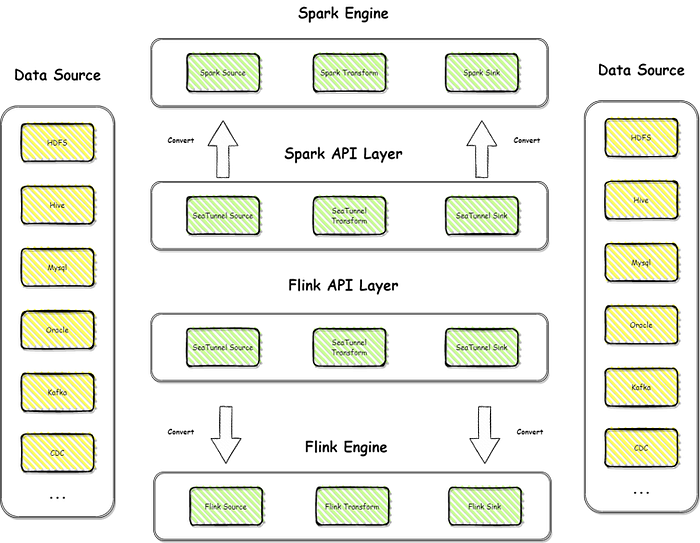
Additionally, this architecture has its drawbacks when handling long tasks for various reasons. For example, the slow startup and shutdown speed of the computing engine leads to longer task startup and shutdown times. Moreover, certain features of the computing engine, such as checkpointing, also affect long tasks. However, the V1 architecture of Apache SeaTunnel also has its advantages, such as the rich computing capabilities provided by Spark and Flink, enabling complex data processing operations.
03 Architecture of Apache SeaTunnel V2
Next, let’s take a look at the architecture of Apache SeaTunnel V2.
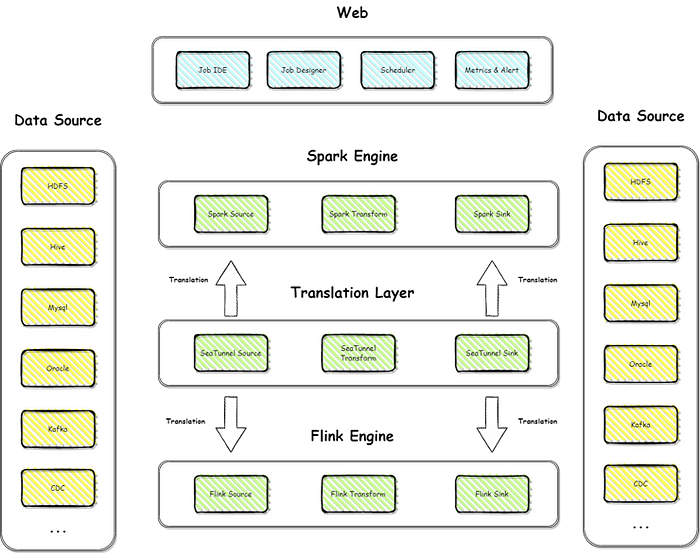
The goal of the V2 architecture is to address some of the issues present in the V1 version, particularly regarding data synchronization speed and handling of long tasks. The V2 architecture consists of several components, including data source connectors, task submission engine, task scheduler, and metadata storage.
The data source connectors are responsible for providing various types of data source connections for data synchronization. The task submission engine is responsible for submitting data synchronization tasks to the computing engine for execution. The task scheduler is responsible for scheduling data synchronization tasks according to predefined time or event triggers. The metadata storage is responsible for storing task-related metadata, such as task configurations and statuses.
04 Workflow of Apache SeaTunnel
The workflow of Apache SeaTunnel can be divided into two main parts: the execution flow of Apache SeaTunnel and the execution flow of connectors.

First, let’s look at the execution flow of Apache SeaTunnel. The process starts with the processing of data sources (source connectors) from different computing engines. SeaTunnel translates the source connectors, allowing them to perform data reading. Next, the transform connectors standardize the data. Finally, the sink connectors perform the final data writing, transferring the data to the target end. This is the entire execution flow of Apache SeaTunnel.
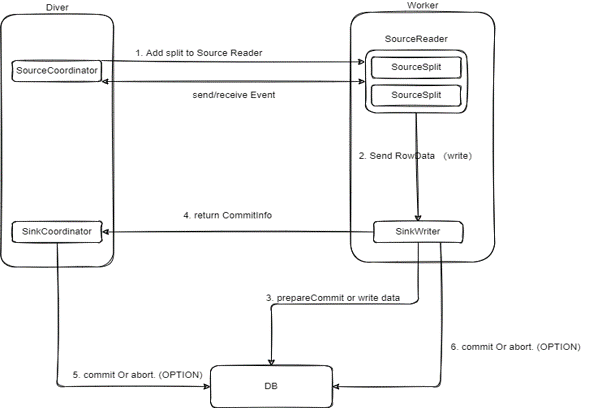
Next, let’s examine the execution flow of connectors. Connectors primarily consist of drivers and workers. In the driver, the SourceCoordinator manages the distribution of source splits to the worker side. The source split emulator sends the split to the source reader for data reading. The source reader, after reading the data, sends it to the SinkWriter. Upon receiving the data, the SinkWriter processes distributed snapshots and writes the processed data to the target end. This is the connector execution flow of Apache SeaTunnel.
05 Engine Independent Connector API
The architecture of Apache SeaTunnel V2 includes six core elements. The first element is the Engine Independent API, specifically designed for data integration scenarios to decouple computing engines.

This API covers four main aspects:
- Multiple engine support: Defines a common API to solve the issue of different computing engines requiring different connectors, enabling the same code to execute on different computing engines.
- Multi-version support for computing engines: Decouples connectors from engines using a translation layer to address the need for extensive connector upgrades when supporting new versions of computing engines.
- Resolving the streaming and batch integration problem: This API provides a unified approach for stream and batch processing, allowing new connectors to support both streaming and batch data synchronization by implementing this unified API.
- JDBC multiplexing and database log multi-table parsing: Apache SeaTunnel supports multi-table or whole-database synchronization, addressing the problem of slow synchronization due to excessive JDBC connections. It also supports multi-table or whole-database log parsing, resolving the issue of duplicate parsing in CDC scenarios.
06 Connector Translation
The fifth core element is the connector translation layer. This translation layer allows the wrapping of connectors implemented based on Apache SeaTunnel’s API into a Spark connector,

for example. This enables running connectors like Hudi on the Spark engine. The implementation principle is the same for Flink as well.
Lastly, let’s discuss the abstraction at the API layer. First, there is the API abstraction at the source layer. This abstraction introduces Boundedness, supporting a unified API for real-time and offline processing.
By introducing SourceReader and SourceSplit, parallel reading is supported. Apache SeaTunnel will further support parallel optimization for source-sink transforms to improve throughput. The introduction of SourceSplit and Enumerator aims to support dynamic shard discovery. SupportCoordinate and SourceEvent are introduced to address coordination reading issues.
Lastly, distributed snapshot capability is also supported by Apache SeaTunnel in the Spark engine to enable state storage and recovery. Under the new source API, two specific sources have been implemented.
The first one is CoordinatedSource, which distributes information such as checkpoints and stream-batch conditions to the SourceReader in the ReaderThread.
The second source is ParallelSource, which supports parallel processing and requires defining partition logic and custom partition algorithms in the connector. It also supports concurrent processing.
07 SeaTunnel Sink Connector
The second part is about the “pipeline” process, which includes some fixed elements. On one hand, it serves as an internal standard, and on the other hand, it learns from open source and incorporates those elements. Regarding the Sink part, Apache SeaTunnel’s design combines the concept of source connectors to achieve exactly-once semantics.
The abstraction of the Sink API can be divided into five main parts:
Sink Writer, State Storage, Distributed Transactions, Committer, and Aggregate Committer.
The Sink Writer is responsible for receiving upstream data and writing it to the target end.
State Storage supports storing the state in components like HDFS, allowing recovery and restart of synchronization tasks after failures.
Distributed Transactions in Apache SeaTunnel’s Sink support two-phase commit and integrate with the Checkpoint mechanism to ensure exactly-once semantics, ensuring data is written only once.
The Committer allows individual tasks to independently commit transactions.
Aggregate Committer supports aggregating metrics for Sink tasks when using the Checkpoint mechanism in Spark engine.
08 SeaTunnel Sink Commit
In the new introduced Sink API, there are three types of commit approaches.
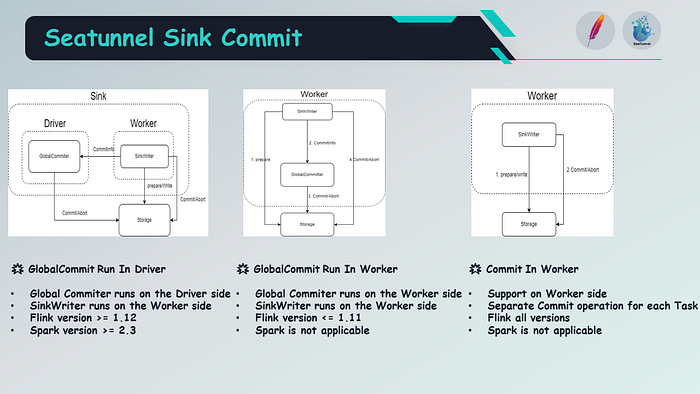
The first one is GlobalCommit Run In Driver, which runs on the driver side. The global committer executes on the driver side, while the Sink Writer runs on the worker side. There are some limitations and compatibility restrictions for different versions of Flink and Spark.
The second one is GlobalCommit Run In Worker, where both the global committer and the Sink Writer run on the worker side. However, it is not applicable to Spark and only supported in Flink versions earlier than 1.11.
The last one is Commit In Worker, which supports running on the worker side, allowing each task to independently perform commit operations. This method is applicable to all Flink versions but not supported in Spark. Therefore, these are the abstractions regarding the Sink API, and the specific implementation depends on current constraints.
09 SeaTunnel Table & Catalog
In the initial architecture diagram, we actually used Azkaban because, at that time, we didn’t have much time to test different products. So we chose the simplest option, Azkaban, as our cluster resource scheduling tool.
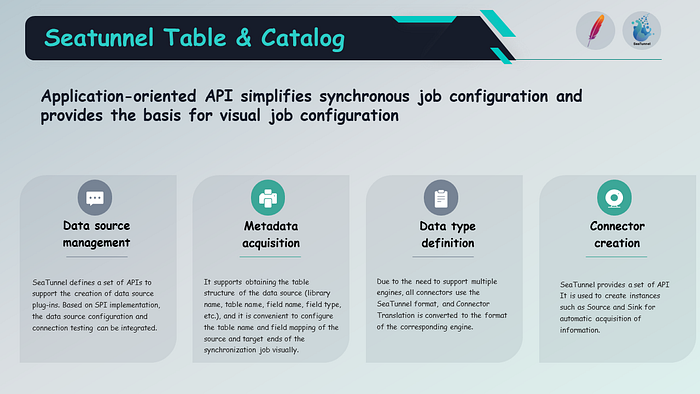
Regarding the API abstraction of Table and Catalog, it aims to simplify the configuration of synchronization jobs and provide a simplified interface for applications.
The interface primarily includes four functionalities: data source management, metadata retrieval, data type definition, and connector creation. Connector creation is used to create instances like source and sink, metadata retrieval is used to obtain metadata of tables and databases, and data type definition allows defining data types through the Table Catalog API. Data source management registers metadata of tables and databases, providing metadata management functionalities.
The API abstraction of Table and Catalog supports multiple engines to reduce the usage cost for enterprise users. Currently, it supports Flink, Spark, and Apache SeaTunnel’s self-developed Zeta engine.
For the Flink engine, it supports multiple versions and naturally integrates with Flink’s Checkpoint mechanism and distributed snapshot algorithm. For the Spark engine, it supports micro-batch processing and provides the Checkpoint mechanism to support the features of aggregate commit. Apache SeaTunnel provides a data synchronization engine designed specifically for data synchronization scenarios, providing an opportunity for enterprises without a big data environment to choose.
This year, Apache SeaTunnel has introduced its own Zeta engine, which guarantees high throughput, low latency, and strong consistency for synchronization jobs.
10 SeaTunnel Zeta Architecture
However, it also has some issues, such as the inability to manage various scripts effectively. The design concept of Apache SeaTunnel Zeta engine is as follows:
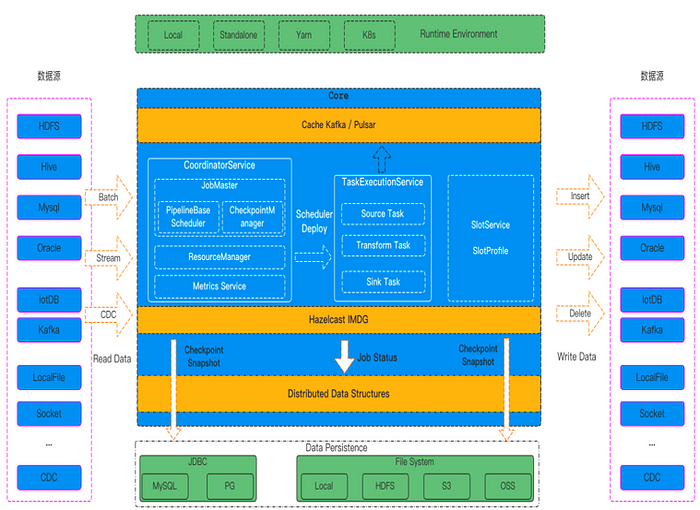
Firstly, it aims to provide simple and easy-to-use features. With the Zeta engine, users can reduce dependencies on third-party services and do not need to rely on components like ZooKeeper and HDFS for cluster management, state snapshot storage, and high availability. This way, even without these components, companies can still use Apache SeaTunnel.
Secondly, the Zeta engine achieves resource saving through CPU-level Dynamic Thread Sharing. For real-time synchronization, if there are many tables to synchronize but each table has a small amount of data, the Zeta engine can reduce unnecessary thread creation and save system resources. It places these synchronization tasks in shared threads and minimizes the number of connections to JDBC to avoid impacting synchronization speed. For CDC scenarios, it implements the reuse of log processing and parsing resources, avoiding redundant log parsing and saving computational resources.
Thirdly, stability is a key consideration. Apache SeaTunnel’s Zeta engine performs Checkpoint and fault tolerance at the pipeline level, ensuring that if a task fails, it only affects tasks related to it, avoiding the failure or rollback of the entire job. In addition, the Zeta engine supports data caching, automatically caching the data read from the source end. Even if the target end fails and data cannot be written, it does not affect the reading of data from the source end, preventing the deletion of remote data due to expiration. Moreover, the Zeta engine’s execution plan optimizer primarily focuses on reducing data network transmission. It optimizes the execution plan and minimizes the performance impact of data serialization and deserialization to achieve rapid data synchronization. It also supports speed adjustment to synchronize data at a reasonable pace.
Finally, the Zeta engine supports data synchronization for all scenarios, including full-incremental synchronization in offline batch synchronization, real-time synchronization, and CDC synchronization.
11 SeaTunnel Zeta Services
SeaTunnel Zeta mainly consists of a set of data synchronization processing APIs and core computing engines, including three main services: CoordinatorService, TaskExecutionService, and SlotService.
🌟 CoordinatorService
CoordinatorService is the master service of the cluster, responsible for generating the LogicalDag, ExecutionDag, and PhysicalDag of jobs, as well as scheduling and monitoring job statuses. It includes the following components:
- JobMaster: Responsible for generating the LogicalDag, ExecutionDag, and PhysicalDag of jobs and scheduling their execution using the PipelineBaseScheduler.
- CheckpointCoordinator: Responsible for the Checkpoint process control of jobs.
- ResourceManager: Responsible for job resource allocation and management. Currently, it supports the Standalone mode and will support On Yarn and On K8s in the future.
- Metrics Service: Responsible for statistics and aggregation of job monitoring information.
🌟 TaskExecutionService
TaskExecutionService is the worker service of the cluster, providing a runtime environment for each task in the job. TaskExecutionService utilizes Dynamic Thread Sharing technology to reduce CPU usage.
🌟 SlotService
SlotService runs on each node of the cluster and is mainly responsible for resource allocation, request, and recovery.
The main features of the Apache SeaTunnel architecture are high throughput, accuracy, and low latency.
High throughput is reflected in the parallel processing of source, transform, and sink connectors. By parallelizing data synchronization, SeaTunnel improves the throughput of data synchronization.
Accuracy is achieved through the distributed snapshot algorithm implemented by SeaTunnel and mechanisms such as two-phase commit and idempotent writes, ensuring exactly-once semantics.
Low latency is reflected in the real-time processing and micro-batch processing capabilities provided by Spark and Flink engines, enabling SeaTunnel to achieve low-latency data synchronization.
12 Apache Paimon
Next, let’s introduce Apache Paimon. Apache Paimon is a recently incubating project in the Apache Software Foundation. It was originally known as Flink Table Store and officially entered the Apache Software Foundation on March 12th this year, renamed as Paimon. The name Paimon comes from an NPC in the game Genshin Impact. As the Flink community matures and develops, more and more companies are using Flink for real-time data processing to improve data timeliness and achieve real-time business effects. At the same time, in the big data field, data lake technology is becoming a new trend. Many companies, including Bilibili (B站), are adopting the Lakehouse architecture to build the next generation of data warehouses. Therefore, the Flink community hopes to introduce a new generation of streaming data warehouse technology by combining Flink’s stream processing capabilities with Paimon’s storage architecture, enabling data to truly run in data services and providing users with a real-time and offline integrated development experience.
Currently, mainstream data lake storage projects in the market are mainly designed for batch processing scenarios and cannot meet the requirements of streaming data warehouses. Therefore, over a year ago, the Flink community introduced a project called Flink Table Store, which is a streaming and real-time data lake storage. In summary, Apache Paimon is a streaming data lake storage technology that provides users with high throughput, low latency data ingestion and streaming subscription capabilities, and the ability to query data in Paimon tables. Paimon adopts open data formats that are consistent with mainstream data lake storage formats, and it can integrate with major big data engines such as Apache Spark, Apache Flink, Apache Doris, and more engines such as Doris DB and StarRocks in the future, promoting the popularization and development of the streaming Lakehouse architecture in the big data field.
Paimon mainly consists of four elements:
- Open data formats: Paimon manages metadata in a storage-less manner and uses file formats such as Parquet, ORC, Avro, etc. It supports multiple mainstream engines like Hive, Flink, Spark, Trino, Presto, and will support more engines like Doris DB and StarRocks in the future.
- Large-scale real-time update capability: Due to Paimon’s underlying LSM (Log-Structured Merge) data structure and append-only write capability, it can achieve good performance in large-scale data update scenarios. The latest version of Paimon has been integrated with Flink CDC (Continuous Growth Controller), providing two suitable capabilities through the Flink data stream. The first capability is real-time synchronization of a single table from MySQL to a Paimon table and real-time synchronization of upstream MySQL table changes to downstream Paimon tables. The second capability is supporting real-time synchronization of table-level and whole-database-level table structure and data in MySQL while reusing resources as much as possible to reduce resource consumption during data synchronization. Therefore, by integrating Paimon with Flink CDC, business data can be efficiently and simply streamed into the data lake.
- Partial table update capability: It is mainly aimed at wide table business scenarios.
- Stream-batch integrated data entity: Paimon, as a stream-batch integrated storage, provides capabilities for streaming read, streaming write, batch read, and batch write. Using Paimon, you can build streaming data processing pipelines and persist data into the storage. For example, in Flink stream processing jobs, you can perform OLAP queries on both historical and real-time data in Paimon tables. Paimon also supports historical partition backfilling of Paimon tables through Flink, enabling batch read and write operations. These are the four main elements of Paimon.
Now let’s briefly understand the file layout of Paimon. The file layout of Paimon consists of snapshot files. The entire file layout is similar to Apache Iceberg, where snapshots are composed of manifest lists, and manifest lists contain information about schemas. Manifest lists consist of multiple manifests. Each manifest is determined by a bucket, which corresponds to a data structure of an LSM tree. Therefore, this is the layout of Paimon files.
For each bucket, it is actually an independent LSM tree and corresponds to a Kafka message partition. Paimon innovatively combines data lake storage with LSM trees and leverages optimized storage formats (such as ORC) to achieve large-scale real-time update capability.
The file organization structure of LSM tree is shown in the right figure. As can be seen, this data structure brings high-performance update capability, and the merge operation of LSM tree ensures performance and stability. In testing, a bucket can achieve 50K RPS (requests per second). The second capability is high-performance querying because the data in the LSM tree is ordered, enabling query optimization through data skipping. This is a characteristic of the underlying LSM file organization in Paimon.
Next, let’s introduce the merge engine in Paimon. The merge engine in Paimon is used to merge write data with the same component. Paimon mainly supports the following three merge modes:
- Deduplicate: The default merge engine is deduplicate, which means only the latest record is retained, and other records with the same primary key (PK) are discarded. If the latest record is a DELETE record, all data with the same PK will be deleted.
- Partial update: When specifying ‘merge-engine’ = ‘partial-update’ during table creation, it means using the partial update table engine, allowing multiple Flink streaming tasks to update different columns of the same table, eventually achieving complete data updates for a row. In the business scenarios of data warehousing, a wide table data model is often used. A wide table model typically refers to a model table that associates business entity-related metrics, dimension tables, and attributes. It can also refer to combining multiple fact tables and multiple dimension tables into a wide table. For wide table models, partial update is very suitable, and it is also relatively simple to build wide tables. For streaming read scenarios, the partial-update table engine needs to be used together with Lookup or full compaction Changelog Producer, and it does not accept and process DELETE messages. Paimon’s Partial-Update merge engine can merge multiple streams in real-time based on the same primary key, forming a large wide table in Paimon. With the help of LSM’s delayed Compaction mechanism, merging can be achieved at a lower cost. The merged table can provide batch read and stream read capabilities:
- Batch read: During batch reading, the reading merge can still perform Projection Pushdown, providing high-performance queries.
- Stream read: The downstream can see complete and merged data instead of partial columns.
3.Aggregation: When specifying ‘merge-engine’ = ‘aggregation’ during table creation, it means using the aggregation table engine. Through aggregation functions, some pre-aggregation can be done. Each column, except for the primary key, can specify an aggregation function. Data with the same primary key can be pre-aggregated according to the specified aggregation function for each column. If not specified, the default is last-non-null value, and null values will not overwrite. The Agg table engine also needs to be used together with Lookup or full compaction Changelog Producer, and it should be noted that except for the SUM function, other Agg functions do not support Retraction.
Next, let’s talk about the supported Changelog producers in Paimon. Regardless of how the input is updated or how the business requires merging (such as Partial-Update), using the Changelog generation function of Paimon, you can always obtain completely correct change logs during stream reading.
When dealing with primary key tables, why do you need complete Changelog?
- Your input is not a complete Changelog, for example, it may lack UPDATE_BEFORE (-U), or there may be multiple INSERT data for the same primary key. This will cause issues with aggregating stream reads downstream, as multiple data with the same primary key should be considered updates rather than duplicate calculations.
- When your table is a Partial Update, the downstream needs to see complete and merged data in order to perform correct stream processing.
The supported Changelog producers in Paimon mainly include:
- None: If not specified, the default is none, which has higher costs.
- Input: When the source is the binlog of the business database, meaning that the input to the Paimon table writer task is a complete Changelog, you can fully rely on the input Changelog and save it to Paimon’s Changelog file, which is provided to downstream stream reading by Paimon Source.
- Lookup: When the input is not a complete Changelog and you don’t want to generate Changelog through the Normalize node during downstream stream reading, you can generate Changelog during data writing through the Lookup method. This Changelog Producer is currently in an experimental state.
- Full compaction: The Writer generates complete Changelog after compaction and writes it to the Changelog file. The interval and frequency of compaction can be controlled by setting the configuration parameter ‘changelog-producer.compaction-interval’. However, this parameter is planned to be deprecated, and it is recommended to use ‘full-compaction.delta-commits’, where the default value is 1, indicating that compaction is performed after each commit.
If you find that the cost of generating Changelog in real-time using Lookup is too high, you can decouple Commit and Changelog generation by using Full-Compaction and corresponding longer delays, generating Changelog at a very low cost.
Next, let’s compare Paimon with other data lake products. From the diagram, we can see that data lakes such as Iceberg, Delta, Hudi have lower storage costs and update latencies ranging from hours to minutes. The update schemes include Copy On Write and Merge On Read. For high-performance querying, manual sorting of the data lake is required. ClickHouse is an OLAP system with higher storage costs but provides fast update latency and very fast query performance. Based on the LSM architecture, it achieves excellent update efficiency and query acceleration. In summary, Paimon can be seen as a data lake version of ClickHouse.
Next, let’s briefly introduce the Java API of Paimon, including reading and writing APIs, which are divided into batch read, batch write, stream read, and stream write.

Batch reading is divided into two stages: the first stage generates plan splits on a central node, and the second stage reads the data of each split through distributed tasks.
Batch writing is divided into two stages: the first stage writes data through distributed tasks to generate Commit messages, and the second stage collects all Commit messages on a central node for Commit. If a Commit fails, you can call the abort API for rollback.
For stream reading, the difference from batch reading is that StreamTableScan can continuously scan and generate splits. StreamTableScan also provides the ability for Checkpoint and Restore, allowing users to store the correct state during stream reading.
For stream writing, the difference from batch writing is that StreamTableCommit can perform continuous Commit and supports exactly-once semantics.
Here, we have several key elements. Then, we will introduce its main use cases. With these APIs, such as write and commit, we can implement the Paimon connector for Apache SeaTunnel. Currently, the connector is still in its basic version and only implements the functions of batch reading and writing. We will demonstrate this process through a video, which shows how to read and write Paimon data in batches, simply by specifying the table path, table name, and field names.
On the Sink side, setting the address, database name, and table name of the warehouse is also the same operation.
13 Apache Paimon Connector
With the basic implementation using Apache SeaTunnel, we can write data to Paimon. The Paimon connector mainly includes the Paimon source reader and Sink writer. The Sink writer is used for writing data. It calls the BatchTableWrite method mentioned earlier to write records, obtain commit messages, and then perform the commit operation.
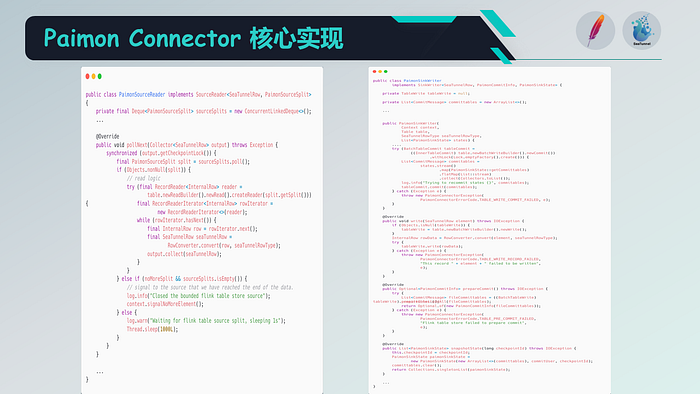
Therefore, the Paimon Sink writer has already implemented this process. As for the Paimon source reader, it can read and split Paimon data based on record equivalence. These are the two components of the Paimon connector, implementing the functionalities of Sink and Source.
14 Apache SeaTunnel
Lastly, let’s discuss the community plans for Apache SeaTunnel. As a data integration platform, SeaTunnel continuously focuses on addressing the needs and issues in the field of data integration, aiming to provide a user-friendly experience in terms of the number of heterogeneous data sources, integration performance, and ease of use.
🌟 V2 version doubles the number of connectors:
- Flink and Spark connectors are upgraded to the V2 version.
- V2 version will support 80+ connectors by 2023.
🌟 Release of SeaTunnel Web:
- Visual job management.
- Programmatic and guided job configuration.
- Internal scheduling (primarily for simple tasks using Crontab) and third-party scheduling (mainly using Dolphin Scheduler).
🌟 Release of SeaTunnel Engine:
- More efficient resource usage by reducing JDBC connections and duplicate reading of binlogs.
- Splitting tasks into pipelines, where errors in one pipeline will not affect others, and independent restart operations are supported.
- Faster completion of overall synchronization tasks with the help of shared threads and underlying processing.
- Improved monitoring metrics, monitoring the running status of connectors and including data quantity and quality.
