Building a Data Middle Platform with Apache SeaTunnel: A Journey into Open Source Contribution
This year, the company decided to build its own data platform due to a fortunate coincidence. Building the platform inevitably involved data integration. The first challenge we faced was the selection of data integration technology. We conducted in-depth research on several mature open-source engines available in the market, considering factors like community activity, data source adaptability, and synchronization efficiency.
Ultimately, after internal discussions, we chose Apache SeaTunnel as the foundation for our data integration.
Contribution Experience
Before learning about Apache SeaTunnel, I had little involvement in open-source projects, mostly using them as needed for work. Although I was interested in contributing to open-source, I hadn’t had the opportunity to do so. SeaTunnel was in a phase of rapid iteration, which I saw as a chance to get involved.
Encountering a Problem
In July this year, we encountered a problem while using MySql-CDC for data synchronization at our company. Initially, the synchronization tasks ran smoothly, but after some time, we noticed a significant amount of GC (Garbage Collection) output in the server logs, indicating low efficiency in memory recycling.
Attempting to Solve
Since our batch jobs had been completing successfully up to that point, we first ruled out misuse as a cause. Identifying it as a memory issue, we tried reducing the JVM heap memory parameters and enabled JMX memory monitoring. We reran the CDC task to replicate the problem, and as expected, it reoccurred. Memory monitoring revealed that the heap memory continued to grow during the CDC task execution, as shown in the following image:
This led us to conclude that the issue was likely due to a memory leak in the code. We needed to analyze the current JVM memory situation in detail. I used jmap to dump the heap memory to a local file and analyzed it with MemoryAnalyzer. The findings are illustrated in the following image:
The image above shows the Leak Suspects in MemoryAnalyzer, highlighting the larger objects in the heap that were likely causing the abnormal memory usage. A BinaryLogClient object, occupying about 1.7 GB of memory, couldn't be reclaimed. Further analysis of its associated objects is shown below:
The MySqlBinlogSplitReadTask seemed to be holding this reference. Further analysis of this object's references is shown in the next image:
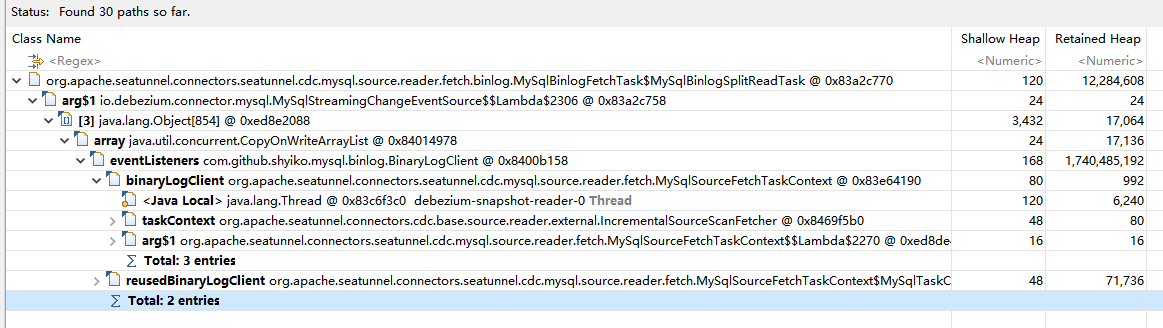
Identifying the Cause
Ultimately, we discovered that within the BinaryLogClient object, there was an eventListeners event listener that was causing issues. With this clue, we delved into the source code for a deeper investigation.
Reading the Source Code
Through the source code analysis, we learned that eventListeners is used during the data synchronization extraction phase to listen to binlog changes, collecting change data into a queue for subsequent task processing.
The MySqlBinlogSplitReadTask is designed to compensate for changes generated during the CDC snapshot phase. Each execution of this task registers a current event listener with the BinaryLogClient. When a binlog change is detected, the change data is collected into the respective shard's queue. Each task only processes binlog records within its shard range and ends after compensating. However, as shown in Figure 3, many tasks were not released, which was inconsistent with the design.
The root cause became clear: the BinaryLogClient, being reused, registered event listeners for compensation tasks but did not remove them after task completion. This led to continuous writing of binlog changes into respective shard queues by unremoved listeners, which could not be consumed and eventually caused continuous memory growth.
Solving the Problem
Based on the analysis, I modified the corresponding code. During the initialization of the snapshot
shard tasks, I manually unregistered the listeners from the previous shard and then tested the code. Fortunately, the memory curve returned to normal, as illustrated in the following image:
With this local fix, the issue seemed resolved. However, considering the open-source nature of the project, I realized that this fix would only be temporary for our local version and would need to be reapplied with each update. Also, other users of SeaTunnel might encounter the same problem. Thus, I decided to take my first step in contributing to open source by submitting this discovery and solution to the community, hoping it would be accepted and beneficial for others.
Here is the Pull Request (PR) I submitted for this issue:
The PR journey wasn’t smooth, as the initial code fix lacked maintainability, leading to feedback for adjustments from community experts. After further modifications, the PR was successfully merged.
This experience, though it had its challenges, ended positively. Seeing my PR accepted by the community brought immense joy and motivation to tackle more problems. This journey also illustrates that contributing to open source isn’t as daunting as one might think. Without trying, you’ll never know the outcome.
How to Contribute to the Community
There are various ways to contribute to an open-source community: code contributions, documentation, identifying and reporting issues, and answering questions. Today, I’d like to share how to contribute your code to SeaTunnel, specifically through PRs (Pull Requests).
Since the environment shifts from a company to a community setting, the corresponding standards will differ. Without uniform standards, open-source contributions can become chaotic.
First, it’s essential to understand the process and standards for submitting a PR to SeaTunnel. You can refer to the article: “【Building Open Source】A Step-by-Step Guide to Contributing a SeaTunnel PR,” which is incredibly detailed. Based on this article, I’ve added some points to prevent others from encountering similar issues. The process involves several steps:
● Fork the project
● Clone the forked project to your local environment
● Create a new branch based on the development branch ‘dev’, with a name reflecting the content of the changes
● Modify the code and test it
In SeaTunnel, there are a few steps for code testing. First is local testing: after making code changes, you need to run the code locally or deploy it to a server to ensure the functionality is working correctly.
If it’s a new feature, you need to add corresponding end-to-end (e2e) test cases. Note that tests related to data sources, Flink, and Spark engines in e2e arerun on Docker, so you’ll also need a local Docker environment for these types of tests. For more information on this, you can refer to the official documentation of TestContainers.
● Code format check The article on PR contributions doesn’t mention code format checks. In SeaTunnel, we use the Maven plugin ‘spotless’ to standardize our code format. First, you need to execute the command mvn spotless:check. If there's any code that doesn't pass the format check during compilation, you must use mvn spotless:apply to format the code.
Here is an example of the output when ‘spotless check’ fails, indicating that certain lines of code in a specific class did not pass the format check:
After identifying code that failed the check, use ‘spotless apply’ to format the code:
● Submit your code with a commit message following the format [Feature/Bugfix/Improve/…][Module Name].
● Create an issue describing the problem you encountered, including your runtime environment, engine version, configuration information, and exception logs.
A tip for submitting issues: Including server-side logs can help the community in troubleshooting.
● Create a PR on GitHub, adhering to the format [Feature/Bugfix/Improve/…][Module Name] for the title. The PR should clearly describe the problem solved and link to the related issue.
● Wait for community members
to review your code. If modifications are required, make the necessary changes in the same branch and push the updates.
● Wait for the Continuous Integration (CI) checks to complete. After passing these checks, your PR will undergo final review and approval.
This summarizes my journey of contributing to the SeaTunnel community and my experiences. I believe that sharing my story can help demystify open-source contributions and encourage more people to participate. Contributing to open source is not as remote and challenging as it might seem. The sense of achievement and community involvement is truly rewarding. I hope my experience can inspire more people to take an active part in open-source projects.
By sharing these insights and experiences, I aim to convey that open-source contribution is accessible and impactful. Whether it’s through coding, documentation, problem-solving, or community engagement, each contribution enriches the project and fosters a collaborative environment. I encourage everyone interested in open-source development to take that first step and discover the opportunities and rewards it offers.
